Mario Solana Ezquerra - Mar, 03/05/2022 - 11:00

Niño ante un tablero de ajedrez gigante.
El aprendizaje automático se divide en tres grandes áreas: el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo. Hoy nos vamos a centrar en el aprendizaje por refuerzo. Este tipo de aprendizaje automático es el más fácil de entender de los tres ya que su funcionamiento se basa en recompensar al algoritmo cuando consideramos que lo ha hecho bien y penalizarlo en caso contrario. Veamos el esquema general de un algoritmo de este tipo:
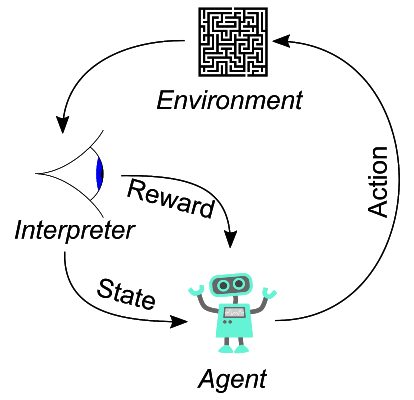
Esquema del aprendizaje por refuerzo. Fuente: Wikipedia.
El entorno o ambiente (environment) es el escenario donde se desarrolla todo el proceso. El agente (agent) es el protagonista y el que se encargar de realizar acciones (action) sobre el entorno. Estas acciones llevan asociadas unas recompensas (reward) y modifican el entorno haciendo que evolucione a un nuevo estado (state). La clave es encontrar una buena estrategia (llamada política) para que el agente tome acciones que permitan conseguir el objetivo del proceso. Las recompensas incentivan o penalizan las acciones para que el agente cada vez actúe de forma más precisa en pos de conseguir el objetivo. Este objetivo puede ser conseguir la máxima recompensa posible o llegar a un estado final, por ejemplo, el jaque mate en el ajedrez.
Antes de hablar de aprendizaje por refuerzo y ajedrez, veamos un breve resumen de la historia del humano contra la máquina dentro del contexto ajedrecístico. Cuando hablamos de máquinas y ajedrez no podemos pasar por alto a El Turco. El Turco fue un autómata, creado en el siglo XVIII, que consistía en un maniquí vestido con una túnica y un turbante, sentado sobre una cabina de madera y que era capaz de jugar al ajedrez de manera autónoma. El Turco fue capaz de ganar a grandes jugadores de la época y, de manera anecdótica, se enfrentó a Napoleón Bonaparte haciéndose con la victoria.

El turco. Fuente: Wikipedia.
Desafortunadamente, todo indica que El Turco era un engaño y que dentro de la cabina había un maestro de ajedrez guiando sus movimientos. El misterio nunca se ha podido desvelar, ya que se calcinó en un incendio.
Damos un gran salto hasta mayo de 1997, por primera vez una máquina gana un match al vigente campeón del mundo de ajedrez. Hablamos de la supercomputadora (del momento) Deeper Blue (IBM) y el azerbaiyano Garry Kaspárov.

Garry Kasparov contra Deep Blue. Fuente: La nación.com
Deeper Blue obtenía un elevado nivel ajedrecístico basándose en la fuerza bruta y es que era capaz de calcular alrededor de 200 millones de posiciones por segundo. El resultado del match fue un peleado 3.5 – 2.5 a favor de la máquina. Un año antes Kaspárov había derrotado a su predecesor Deep Blue, aun así, en esa ocasión acusó a IBM de hacer trampas al contar con jugadores humanos que asistían a la máquina. Tras el encuentro, las máquinas oficialmente superaron al ser humano, pero la diferencia aun no era abismal.
En 2008 aparece una versión primigenia de Stockfish. A lo largo de estos años, Stockfish se ha convertido en el motor de ajedrez más famoso y potente. Es de código abierto por lo que está desarrollado en multitud de plataforma, de hecho, hay aplicaciones para móviles que incluyen este motor de ajedrez. El nivel de ajedrez se suele medir en base a una puntuación denominada ELO. El ELO asociado a Stockfish es de 3546 mientras que la máxima puntuación alcanzada por un humano es de 2882, esta proeza lleva el nombre de Magnus Carlsen, vigente campeón del mundo. En este momento, la brecha que separa a las máquinas de los humanos es insalvable, ya no es necesario un superordenador y es que un simple teléfono móvil es capaz de aplastar al campeón del mundo. Stockfish alcanza su nivel de juego sumando la potencia de cálculo con sofisticaciones a la hora de buscar y descartar jugadas y a la hora de evaluar las posiciones.
En 2017 aparece AlphaZero (DeepMind) un programa basado en aprendizaje por refuerzo. En el caso concreto de aplicar aprendizaje por refuerzo al ajedrez tenemos que el entorno es el tablero de ajedrez y las piezas, el agente es el jugador, las acciones son los movimientos legales que se pueden realizar en cada posición y, lo más complejo, es el sistema de las recompensas que tiene que ver con la evaluación de cada posición. Los programas de aprendizaje por refuerzo aprenden de forma progresiva ejecutándose una y otra vez. De esta forma, AlphaZero consiguió en 4h de aprendizaje el nivel suficiente para derrotar a Stockfish y todo esto sin libros de aperturas ni conocimiento de finales, es decir, aprendió desde cero de manera autónoma. Como curiosidad, mientras que Stockfish analiza 60 millones de posiciones por segundo a AlphaZero le basta con analizar 60 mil.
A día de hoy no es que haya diferencia entre los ajedrecistas humanos y las máquinas, sino que los mejores jugadores del mundo, muchas veces, son incapaces de comprender las jugadas que realizan estos programas y esto se lo debemos en parte al aprendizaje por refuerzo.
Editor: Universidad Isabel I
ISSN 2792-1794
Burgos, España